init 和 main 函数相关特点
init 函数 (没有输入参数、返回值)的主要作用
- 初始化不能采用初始化表达式初始化的变量。
- 程序运行前的注册。
- 实现sync.Once功能。
- 其他
init 顺序
- 在同一个 package 中,可以多个文件中定义 init 方法
- 在同一个 go 文件中,可以重复定义 init 方法
- 在同一个 package 中,不同文件中的 init 方法的执行按照文件名先后执行各个文件中的 init 方法
- 在同一个文件中的多个 init 方法,按照在代码中编写的顺序依次执行不同的 init 方法
- 对于不同的 package,如果不相互依赖的话,按照 main 包中 import 的顺序调用其包中的 init() 函数
- 如果 package 存在依赖,调用顺序为最后被依赖的最先被初始化,例如:导入顺序 main –> A –> B –> C,则初始化顺序为 C –> B –> A –> main,一次执行对应的 init 方法。
所有 init 函数都在同⼀个 goroutine 内执行。 所有 init 函数结束后才会执行 main.main 函数
Go 的数据结构的零值是什么?
-
所有整型类型:0
-
浮点类型:0.0
-
布尔类型:false
-
字符串类型:””
-
指针、interface、切片(slice)、channel、map、function :nil
Go的零值初始是递归的,即数组、结构体等类型的零值初始化就是对其组成元素逐一进行零值初始化。
byte和rune有什么区别
rune和byte在go语言中都是字符类型,且都是别名类型
-
byte 型本质上是 uint8类型的别名,代表了 ASCII 码的一个字符
-
rune 型本质上是 int32型的别名,代表一个 UTF-8 字符
Go struct 能不能比较
需要具体情况具体分析,如果struct中含有不能被比较的字段类型,就不能被比较。
如果struct中所有的字段类型都支持比较,那么就可以被比较。
- 不可被比较的类型:
- slice,因为slice是引用类型,除非是和nil比较
- map,和slice同理,如果要比较两个map只能通过循环遍历实现
- 函数类型
其他的类型都可以比较。
还有两点值得注意:
- 结构体之间只能比较它们是否相等,而不能比较它们的大小
- 只有所有属性都相等而且属性顺序都一致的结构体才能进行比较
Go 语言如何初始化变量
var a int=10
var a=10
a:=10
Go import 的三种方式
一、加下划线:
import 下划线(如:_ “github.com/go-sql-driver/mysql”)
作用:使用[import _ 包路径]只是引用该包,仅仅是为了调用init()函数,所以无法通过包名来调用包中的其他函数。
二、加点(.):
import和引用的包名之间加点(.)操作的含义就是这个包导入之后在调用这个包的函数时,可以省略前缀的包名。
三、别名:
别名操作顾名思义可以把包命名成另一个用起来容易记忆的名字。
与其他语言相比,使用 Go 有什么好处?
- 与其他作为学术实验开始的语⾔不同,Go 代码的设计是务实的。每个功能和语法决策都旨在让程序员的⽣活更轻松。
- Golang 针对并发进行了优化,并且在规模上运行良好。
- 由于单⼀的标准代码格式,Golang 通常被认为比其他语⾔更具可读性。
- ⾃动垃圾收集明显比Java 或 Python 更有效,因为它与程序同时执行。
听说 go 有什么什么的缺陷,你怎么看
- 缺少框架;
- go 语言通过函数和预期的调用代码简单地返回错误,容易丢失错误发生的范围;
- go语言的软件包管理没有办法制定特定版本的依赖库。
Golang的常量取地址
Go 语⾔中,常量⽆法寻址, 是不能进⾏取指针操作的
const i = 100
var j = 123
func main() {
fmt.Println(&j, j)
fmt.Println(&i, i) //panic
} //Go语⾔中,常量⽆法寻址, 是不能进⾏取指针操作的
Golang 的字符串拼接
A. str := 'abc' + '123'
B. str := "abc" + "123"
C. str := '123' + "abc"
D. fmt.Sprintf("abc%d", 123)
答案:B、D
string 和 []byte 如何取舍
string 擅长的场景:
- 需要字符串比较的场景;
- 不需要nil字符串的场景;
[]byte擅长的场景:
- 修改字符串的场景,尤其是修改粒度为1个字节;
- 函数返回值,需要用nil表示含义的场景;
- 需要切片操作的场景;
使用过哪些 Golang 的 String 类库
strings. Builder
Go 语言提供了一个专门操作字符串的库 strings,可以用于字符串查找、替换、比较等。
使用 strings.Builder 可以进行字符串拼接,提供了 writeString 方法拼接字符串,使用方式如下:
var builder strings.Builder
builder.WriteString("asong")
builder.String()
strings.builder 的实现原理很简单,结构如下:
type Builder struct {
addr *Builder // of receiver, to detect copies by value
buf []byte // 1
}
addr 字段主要是做 copycheck,buf 字段是一个 byte 类型的切片,这个就是用来存放字符串内容的,提供的 writeString() 方法就是向切片 buf 中追加数据:
func (b *Builder) WriteString(s string) (int, error) {
b.copyCheck()
b.buf = append(b.buf, s...)
return len(s), nil
}
提供的 String 方法就是将 []byte 转换为 string 类型,这里为了避免内存拷贝的问题,使用了强制转换来避免内存拷贝:
func (b *Builder) String() string {
return *(*string)(unsafe.Pointer(&b.buf))
}
bytes. Buffer
因为 string 类型底层就是一个 byte 数组,所以我们就可以 Go 语言的 bytes.Buffer 进行字符串拼接。bytes.Buffer 是一个一个缓冲 byte 类型的缓冲器,这个缓冲器里存放着都是 byte。使用方式如下:
buf := new(bytes.Buffer)
buf.WriteString("asong")
buf.String()
bytes.buffer 底层也是一个 []byte 切片,结构体如下:
type Buffer struct {
buf []byte // contents are the bytes buf[off : len(buf)]
off int // read at &buf[off], write at &buf[len(buf)]
lastRead readOp // last read operation, so that Unread* can work correctly.
}
因为 bytes.Buffer 可以持续向 Buffer 尾部写入数据,从 Buffer 头部读取数据,所以 off 字段用来记录读取位置,再利用切片的 cap 特性来知道写入位置,这个不是本次的重点,重点看一下 WriteString 方法是如何拼接字符串的:
func (b *Buffer) WriteString(s string) (n int, err error) {
b.lastRead = opInvalid
m, ok := b.tryGrowByReslice(len(s))
if !ok {
m = b.grow(len(s))
}
return copy(b.buf[m:], s), nil
}
切片在创建时并不会申请内存块,只有在往里写数据时才会申请,首次申请的大小即为写入数据的大小。如果写入的数据小于 64 字节,则按 64 字节申请。采用 动态扩展slice 的机制,字符串追加采用 copy 的方式将追加的部分拷贝到尾部,copy 是内置的拷贝函数,可以减少内存分配。
但是在将 []byte 转换为 string 类型依旧使用了标准类型,所以会发生内存分配:
func (b *Buffer) String() string {
if b == nil {
// Special case, useful in debugging.
return "<nil>"
}
return string(b.buf[b.off:])
}
字符串转成 byte 数组,会发生内存拷贝吗
字符串转成切片,会产生拷贝。严格来说,只要是发生类型强转都会发生内存拷贝
翻转含有中文、数字、英文字母的字符串
-
rune关键字,从 golang 源码中看出,它是 int32的别名(-2^31 ~ 2^31-1),比起 byte(-128~127),可表示更多的字符。 -
由于rune可表示的范围更大,所以能处理一切字符,当然也包括中文字符。在平时计算中文字符,可用rune。
-
因此将
字符串转为rune的切片,再进行翻转,完美解决
json 包变量不加 tag 会怎么样?
-
如果变量
首字母小写,则为private。无论如何不能转,因为取不到反射信息。 -
如果变量
首字母大写,则为public。-
不加tag,可以正常转为json里的字段,json内字段名跟结构体内字段原名一致。 -
加了tag,从struct转json的时候,json的字段名就是tag里的字段名,原字段名已经没用。
-
reflect(反射包)如何获取字段 tag?为什么 json 包不能导出私有变量的 tag?
昨天那个在 for 循环里 append 元素的同事,今天还在么?
Golang 语言的自增,自减操作
Golang 语言没++i、–i,只有 i++、i–-。
Printf()、Sprintf()、Fprintf()函数的区别用法是什么
都是把格式好的字符串输出,只是输出的目标不一样。
- Printf(),是把格式字符串输出到标准输出(一般是屏幕,可以重定向)。Printf() 是和标准输出文件 (stdout) 关联的,Fprintf 则没有这个限制。
- Sprintf(),是把格式字符串输出到指定字符串中,所以参数比 printf 多一个 char*。那就是目标字符串地址。
- Fprintf(),是把格式字符串输出到指定文件设备中,所以参数比 printf 多一个文件指针 FILE*。主要用于文件操作。Fprintf() 是格式化输出到一个 stream,通常是到文件。
Go 语言中 cap 函数可以作用于哪些内容?
-
array 返回数组的元素个数;
-
slice 返回 slice 的最⼤容量;
-
channel 返回 channel 的容量;
Golang 语言的引用类型有什么?
Go语言中的引用类型有
-
func(函数类型)
-
interface(接口类型)
-
slice(切片类型)
-
map(字典类型)
-
channel(管道类型)
-
指针类型
通过指针变量 p 访问其成员变量 name,有哪几种方式?
A. p.name
B. (&p).name
C. (*p).name
D. p→name
答案:A、C
for select 时,如果通道已经关闭会怎么样?如果只有⼀个 case 呢?
-
for 循环
select时,如果其中一个 case 通道已经关闭,则每次都会执行到这个 case。 -
如果select里边只有一个case,而这个case被关闭了,则会出现死循环。
Golang 的 bool 类型的赋值
A. b = true
B. b = 1
C. b = bool(1)
D. b = (1 == 2)
赋值正确的是A,D。
首先B选项,int类型不能由bool类型来表示。
其次C选项,bool()不能转化int类型。int和float可以相互转化
空结构体占不占内存空间? 为什么使用空结构体?
空结构体是没有内存大小的结构体。
通过 unsafe.Sizeof() 可以查看空结构体的宽度,代码如下:
var s struct{}
fmt.Println(unsafe.Sizeof(s)) // prints 0
准确的来说,空结构体有一个特殊起点: zerobase 变量。zerobase是一个占用 8 个字节的uintptr全局变量。每次定义 struct {} 类型的变量,编译器只是把zerobase变量的地址给出去。也就是说空结构体的变量的内存地址都是一样的。
空结构体的使用场景主要有三种:
- 实现方法接收者:在业务场景下,我们需要将方法组合起来,代表其是一个 ”分组“ 的,便于后续拓展和维护。
- 实现集合类型:在** Go 语言的标准库中并没有提供集合(Set)的相关实现,因此一般在代码中我们图方便,会直接用 map 来替代:
type Set map[string]struct{}**。 - 实现空通道:在 Go channel 的使用场景中,常常会遇到通知型 channel,其不需要发送任何数据,只是用于协调 Goroutine 的运行,用于流转各类状态或是控制并发情况。
空结构体的使用场景
空结构体(empty struct)是在 Go 语言中一个特殊的概念,它没有任何字段。在 Go 中,它通常被称为匿名结构体或零宽度结构体。尽管它没有字段,但它在某些情况下仍然有其用途,以下是一些常见的空结构体的使用场景:
- 占位符:空结构体可以用作占位符,用于表示某个数据结构或数据集合的存在而不实际存储任何数据。这在某些数据结构的实现中非常有用,特别是在要实现某种数据结构的集合或映射时,但并不需要存储实际的值。
goCopy code// 表示集合中是否包含某个元素的映射
set := make(map[string]struct{})
set["apple"] = struct{}{}
- 信号量:空结构体可以用作信号量,用于控制并发操作。通过向通道发送或接收空结构体,可以实现信号的传递和同步。
goCopy code// 用通道作为信号量
semaphore := make(chan struct{}, 5) // 控制并发数为5
go func() {
semaphore <- struct{}{} // 获取信号量
defer func() { <-semaphore }() // 释放信号量
// 执行并发操作
}()
- 强调结构:有时,空结构体可用于强调某个结构的重要性或存在。它可以用作结构体的标签,表示关注该结构的存在而不是其内容。
goCopy code// 表示一篇文章的元信息,不包含实际内容
type Article struct {
Title string
Author string
PublishedAt time.Time
Metadata struct{} // 空结构体强调元信息的存在
}
- JSON 序列化:在处理 JSON 数据时,有时需要表示一个空对象。可以使用空结构体来表示 JSON 中的空对象(
{})。
goCopy code// 表示一个空的JSON对象
emptyJSON := struct{}{}
jsonBytes, _ := json.Marshal(emptyJSON)
fmt.Println(string(jsonBytes)) // 输出: {}
尽管空结构体没有字段,但它在上述情况下提供了一种轻量级的方式来实现特定的需求,而无需分配额外的内存或定义具体的数据结构。这使得它成为 Go 中的一种有用工具,可以在编写清晰、高效和易于理解的代码时派上用场。
struct 的特点
- 用来自定义复杂数据结构
- Struct 里面可以包含多个字段(属性)
- Struct 类型可以定义方法,注意和函数的区分
- Struct 类型是值类型
- Struct 类型可以嵌套
- GO 语言没有 class 类型,只有 struct 类型
特殊之处
- 结构体是用户单独定义的类型,不能和其他类型进行强制转换
- Golang 中的 struct 没有构造函数,一般可以使用工厂模式来解决这个问题
- 我们可以为 struct 中的每个字段,写上一个 tag。这个 tag 可以通过反射的机制获取到,最常用的场景就是 json 序列化和反序列化。
- 结构体中字段可以没有名字,即匿名字段
Go 的面向对象特性
接口
接口使用 interface 关键字声明,任何实现接口定义方法的类都可以实例化该接口,接口和实现类之间没有任何依赖
你可以实现一个新的类当做 Sayer 来使用,而不需要依赖 Sayer 接口,也可以为已有的类创建一个新的接口,而不需要修改任何已有的代码,和其他静态语言相比,这可以算是 golang 的特色了吧
type Sayer interface {
Say(message string)
SayHi()
}
继承
继承使用组合的方式实现
type Animal struct {
Name string
}
func (a *Animal) Say(message string) {
fmt.Printf("Animal[%v] say: %v
", a.Name, message)
}
type Dog struct {
Animal
}
Dog 将继承 Animal 的 Say 方法,以及其成员 Name
覆盖
子类可以重新实现父类的方法
// override Animal.Say
func (d *Dog) Say(message string) {
fmt.Printf("Dog[%v] say: %v
", d.Name, message)
}
Dog.Say 将覆盖 Animal.Say
多态
接口可以用任何实现该接口的指针来实例化
var sayer Sayer
sayer = &Dog{Animal{Name: "Yoda"}}
sayer.Say("hello world")
但是不支持父类指针指向子类,下面这种写法是不允许的
var animal *Animal
animal = &Dog{Animal{Name: "Yoda"}}
同样子类继承的父类的方法引用的父类的其他方法也没有多态特性
func (a *Animal) Say(message string) {
fmt.Printf("Animal[%v] say: %v
", a.Name, message)
}
func (a *Animal) SayHi() {
a.Say("Hi")
}
func (d *Dog) Say(message string) {
fmt.Printf("Dog[%v] say: %v
", d.Name, message)
}
func main() {
var sayer Sayer
sayer = &Dog{Animal{Name: "Yoda"}}
sayer.Say("hello world") // Dog[Yoda] say: hello world
sayer.SayHi() // Animal[Yoda] say: Hi
}
上面这段代码中,子类 Dog 没有实现 SayHi 方法,调用的是从父类 Animal.SayHi,而 Animal.SayHi 调用的是 Animal.Say 而不是Dog.Say,这一点和其他面向对象语言有所区别,需要特别注意,但是可以用下面的方式来实现类似的功能,以提高代码的复用性
func SayHi(s Sayer) {
s.Say("Hi")
}
type Cat struct {
Animal
}
func (c *Cat) Say(message string) {
fmt.Printf("Cat[%v] say: %v
", c.Name, message)
}
func (c *Cat) SayHi() {
SayHi(c)
}
func main() {
var sayer Sayer
sayer = &Cat{Animal{Name: "Jerry"}}
sayer.Say("hello world") // Cat[Jerry] say: hello world
sayer.SayHi() // Cat[Jerry] say: Hi
}
Go 语言中 ,下面哪个关于指针的说法是错误的?
- 指针不能进行算术运算
- 指针可以比较
- 指针可以是nil
- 指针可以指向任何类型
指针在 Go 语言中只能指向相同类型的结构体或者基本类型。例如,一个 int 类型的变量,只能指向 int 类型的指针。如果尝试将一个不同类型的指针赋给一个变量,将会导致编译错误。
Go 语言的接口类型是如何实现的?
在Go语言中,接口类型是通过类型嵌入(embedding的方式实现的。每个实现了接口的类型的结构体中都有一个隐含的成员,该成员是指向接口类型的指针。通过这种方式,接口实现了对类型的约束和定义。
具体来说,当一个类型实现了某个接口的所有方法后,该类型就被认为是实现了该接口。在结构体中,可以通过嵌入接口类型的方式来实现接口方法。在实现接口方法时,方法的签名需要与接口定义中的方法签名保持一致。
Go 结构体内嵌后的命名冲突
package main
import (
"fmt"
)
type A struct {
a int
}
type B struct {
a int
}
type C struct {
A
B
}
func main() {
c := &C{}
c.A.a = 1
fmt.Println(c)
}
// 输出 &{{1} {0}}
第 7 行和第 11 行分别定义了两个拥有 a int 字段的结构体。 第 15 行的结构体嵌入了 A 和 B 的结构体。 第 21 行实例化 C 结构体。 第 22 行按常规的方法,访问嵌入结构体 A 中的 a 字段,并赋值1。 第 23 行可以正常输出实例化 C 结构体。 接着,将第 22 行修改为如下代码:
func main(){
c:=&C{}
c.a=1
fmt.Println(c)
}
此时再编译运行,编译器报错:
.main. Go:22:3:ambiguousselectorc. A
编译器告知 C 的选择器 a 引起歧义,也就是说,编译器无法决定将 1 赋给 C 中的 A 还是 B 里的字段 a。使用c.a 引发二义性的问题一般应该由程序员逐级完整写出避免错误。
在使用内嵌结构体时,Go 语言的编译器会非常智能地提醒我们可能发生的歧义和错误。
**解决:可以通过:c.A.a 或者c.B.a 都可以正确得到对应的值
关于 switch 语句,下⾯说法正确的有?
A. 条件表达式必须为常量或者整数;
B. 单个case中,可以出现多个结果选项;
C. 需要⽤break来明确退出⼀个case;
D. 只有在case中明确添加fallthrough关键字,才会继续执⾏紧跟的下⼀个case;
答案B、D
Go 编程语言中 switch 语句的语法
switch var1 {
case val1:
...
case val2:
...
default:
.
}
switch{
case 1,2,3,4:
default:
} //case可以有多个数据
变量 var1 可以是任何类型,而 val1 和 val2 则可以是同类型的任意值。类型不被局限于常量或整数,但必须是相同的类型;或者最终结果为相同类型的表达式。
Go 关键字 fallthrough 有什么作用
Fallthrough 关键字只能用在 switch 中。且只能在每个 case 分支中最后一行出现,作用是如果这个 case 分支被执行,将会继续执行下一个 case 分支,而且不会去判断下一个分支的 case 条件是否成立。
package main
import "fmt"
func main() {
switch "a" {
case "a":
fmt.Println("匹配a")
fallthrough
case "b":
fmt.Println("a成功了,也执行b分支")
case "c":
fmt.Println("a成功了,c分支会执行吗?")
default:
fmt.Println("默认执行")
}
}
/*
匹配a
a成功了,也执行b分支
*/
copy 是操作符还是内置函数
Golang中copy是内置函数。
Go 两个接口之间可以存在什么关系?
如果两个接口有相同的方法列表,那么他们就是等价的,可以相互赋值。如果接口 A的方法列表是接口B的方法列表的自己,那么接口B可以赋值给接口A。接口查询是否成功,要在运行期才能够确定。
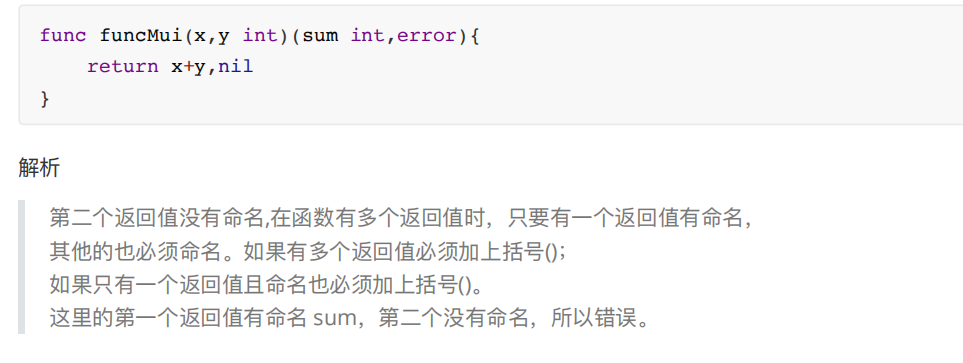
Golang 的返回值命名
Golang 的 iota 如何使用?

- iota在const关键字出现时被重置为0
- const声明块中每新增一行iota值自增1
- 第一个常量必须指定一个表达式,后续的常量如果没有表达式,则继承上面的表达式
数组之间如何进行比较?

for range 的注意点和坑
第一个说法
1.迭代变量。Python中for in 可以直接的到value,但Go的for range 迭代变量有两个,第一个是元素在迭代集合中的序号值key(从0开始),第二个值才是元素值value。
2.针对字符串。在Go中对字符串运用for range操作,每次返回的是一个码点,而不是一个字节。Go编译器不会为[]byte进行额外的内存分配,而是直接使用string的底层数据。
3.对map类型内元素的迭代顺序是随机的。要想有序迭代map内的元素,我们需要额外的数据结构支持,比如使用一个切片来有序保存map内元素的key值。
4.针对切片类型复制之后,如果原切片扩容增加新元素。迭代复制后的切片并不会输出扩容新增元素。这是因为range表达式中的切片实际上是原切片的副本。
5.迭代变量是重用的。类似PHP语言中的i=0;如果其他循环中使用相同的迭代变量,需要重新初始化i。
6.for range使用时,k,v值已经赋值好了,不会因为for循环的改变而改变
package main
import (
"fmt"
)
func main() {
x := []string{"a", "b", "c"}
for v := range x {
fmt.Println(v)
}
}
//输出 0 1 2
第二个说法
应该是一个for循环中作用域的问题
src := []int{1, 2, 3, 4, 5}
var dst2 []*inv
for _, v := range src {
dst2 = append(dst2, &v)
// fmt.println(&v)
}
for _, p := range dst2 {
fmt.Print(*p)
}
// 输出
// 5555
为什么呢, 因为 for-range 中 循环变量的作用域的规则限制
假如取消append()后一行的注释,可以发现循环中v的变量内存地址是一样的,也可以解释为for range相当于
var i int
for j := 0; j < len(src); j++ {
i = src[j]
dst2 = append(dst2, &i)
}
而不是我们想象中的
for j := 0; j < len(src); j++ {
dst2 = append(dst2, &src[j])
}
如果要在for range中实现,我们可以改写为
src := []int{1, 2, 3, 4, 5}
var dst2 []*int
for _, v := range src {
new_v := v
dst2 = append(dst2, &new_v)
// fmt.println(&new_v)
}
for _, p := range dst2 {
fmt.Print(*p)
}
Golang 的断言
Go中的所有程序都实现了interface{}的接口,这意味着,所有的类型如string,int,int64甚至是自定义的struct类型都就此拥有了interface{}的接口.那么在一个数据通过func funcName(interface{})的方式传进来的时候,也就意味着这个参数被自动的转为interface{}的类型。
如以下的代码:
func funcName(a interface{}) string {
return string(a)
}
编译器将会返回:cannot convert a (type interface{}) to type string: need type assertion
此时,意味着整个转化的过程需要类型断言。类型断言有以下几种形式:
直接断言使用
var a interface{}
fmt.Println("Where are you,Jonny?", a.(string))
但是如果断言失败一般会导致panic的发生。所以为了防止panic的发生,我们需要在断言前进行一定的判断
value, ok := a.(string)
如果断言失败,那么ok的值将会是false,但是如果断言成功ok的值将会是true,同时value将会得到所期待的正确的值。示例:
value, ok := a.(string)
if !ok {
fmt.Println("It's not ok for type string")
return
}
fmt.Println("The value is ", value)
另外也可以配合switch语句进行判断:
var t interface{}
t = functionOfSomeType()
switch t := t.(type) {
default:
fmt.Printf("unexpected type %T", t) // %T prints whatever type t has break
case bool:
fmt.Printf("boolean %t\n", t) // t has type bool break
case int:
fmt.Printf("integer %d\n", t) // t has type int break
case *bool:
fmt.Printf("pointer to boolean %t\n", *t) // t has type *bool break
case *int:
fmt.Printf("pointer to integer %d\n", *t) // t has type *int break
}
如何在运行时检查变量类型?
类型开关是在运行时检查变量类型的最佳方式。类型开关按类型而不是值来评估变量。每个 Switch ⾄少包含⼀个 case,⽤作条件语句,和⼀个 default,如果没有⼀个 case 为真,则执行。
func classifier(items ...interface{}) {
for i, x := range items {
switch x.(type) {
case bool:
fmt.Printf("Param #%d is a bool\n", i)
case float64:
fmt.Printf("Param #%d is a float64\n", i)
case int, int64:
fmt.Printf("Param #%d is a int\n", i)
case nil:
fmt.Printf("Param #%d is a nil\n", i)
case string:
fmt.Printf("Param #%d is a string\n", i)
default:
fmt.Printf("Param #%d is unknown\n", i)
}
}
}
精通 Golang 项目依赖 Go modules
https://www.topgoer.cn/docs/golangxiuyang/golangxiuyang-1cmee13oek1e8
Go string 的底层实现
源码包src/runTime/string.go.stringStruct定义了string的数据结构
Type stringStruct struct{
str unsafe.Pointer // 字符串的首地址
len int // 字符串的长度
}
声明:
如下代码所示,可以声明一个string变量赋予初值
var str string
str = "Hello world"
字符串构建过程是根据字符串构建stringStruct,再转化成string。转换的源码如下:
func gostringnocopy(str *byte) string{ //根据字符串地址构建string
ss := stringStruct{str:unsafe.Pointer(str),len:findnull(str)} // 先构造 stringStruct
s := *(*string)(unsafe.Pointer(&ss)) //再将stringStruct 转换成string
return s
}
Go 语言的 panic 如何恢复
recover 可以中止 panic 造成的程序崩溃,或者说平息运行时恐慌,recover 函数不需要任何参数,并且会返回一个空接口类型的值。需要注意的是 recover 只能在 defer 中发挥作用,在其他作用域中调用不会发挥作用。编译器会将 recover 转换成 runtime.gorecover,该函数的实现逻辑是如果当前 goroutine 没有调用 panic,那么该函数会直接返回 nil,当前 goroutine 调用 panic 后,会先调用 runtime.gopaic 函数 runtime.gopaic 会从 runtime. _defer 结构体中取出程序计数器 pc 和栈指针 sp,再调用 runtime.recovery 函数来恢复程序,runtime.recovery 会根据传入的 pc 和 sp 跳转回 runtime.deferproc,编译器自动生成的代码会发现 runtime.deferproc 的返回值不为 0,这时会调回 runtime.deferreturn 并恢复到正常的执行流程。总的来说恢复流程就是通过程序计数器来回跳转。
Go 如何避免 panic
首先明确panic定义:go把真正的异常叫做 panic,是指出现重大错误,比如数组越界之类的编程BUG或者是那些需要人工介入才能修复的问题,比如程序启动时加载资源出错等等。
几个容易出现panic的点:
- 函数返回值或参数为指针类型,nil, 未初始化结构体,此时调用容易出现panic,可加 != nil 进行判断
- 数组切片越界
- 如果我们关闭未初始化的通道,重复关闭通道,向已经关闭的通道中发送数据,这三种情况也会引发 panic,导致程序崩溃
- 如果我们直接操作未初始化的映射(map),也会引发 panic,导致程序崩溃
- 另外,操作映射可能会遇到的更为严重的一个问题是,同时对同一个映射并发读写,它会触发 runtime.throw,不像 panic 可以使用 recover 捕获。所以,我们在对同一个映射并发读写时,一定要使用锁。
- 如果类型断言使用不当,比如我们不接收布尔值的话,类型断言失败也会引发 panic,导致程序崩溃。
- 如果很多时候不可避免地出现了panic, 记得使用 defer/recover
defer 的几个坑
func main() {
fmt.Println(test())
}
func test() error {
var err error
defer func() {
if r := recover(); r != nil {
err = errors.New(fmt.Sprintf("%s", r))
}
}()
raisePanic()
return err
}
func raisePanic() {
panic("发生了错误")
}
为什么输出****?
package main
import (
"fmt"
)
func main() {
defer func() {
if err := recover(); err != nil{
fmt.Println(err)
}else {
fmt.Println("fatal")
}
}()
defer func() {
panic("defer panic")
}()
panic("panic")
}
结果
defer panic
分析
panic仅有最后一个可以被revover捕获。
触发panic("panic")后defer顺序出栈执行,第一个被执行的defer中 会有panic("defer panic")异常语句,这个异常将会覆盖掉main中的异常panic("panic"),最后这个异常被第二个执行的defer捕获到。
package main
import "fmt"
func function(index int, value int) int {
fmt.Println(index)
return index
}
func main() {
defer function(1, function(3, 0))
defer function(2, function(4, 0))
}
这里,有4个函数,他们的index序号分别为1,2,3,4。
那么这4个函数的先后执行顺序是什么呢?这里面有两个defer, 所以defer一共会压栈两次,先进栈1,后进栈2。 那么在压栈function1的时候,需要连同函数地址、函数形参一同进栈,那么为了得到function1的第二个参数的结果,所以就需要先执行function3将第二个参数算出,那么function3就被第一个执行。同理压栈function2,就需要执行function4算出function2第二个参数的值。然后函数结束,先出栈fuction2、再出栈function1.
所以顺序如下:
- defer压栈function1,压栈函数地址、形参1、形参2(调用function3) –> 打印3
- defer压栈function2,压栈函数地址、形参1、形参2(调用function4) –> 打印4
- defer出栈function2, 调用function2 –> 打印2
- defer 出栈 function1, 调用 function1–> 打印1
3
4
2
1
**
Go程序中的包是什么?
包(pkg)是 Go 工作区中包含 Go 源⽂件或其他包的目录。源文件中的每个函数、变量和类型都存储在链接包中。每个 Go 源文件都属于⼀个包,该包在文件顶部使⽤以下命令声明:
package <packagename>
您可以使⽤以下⽅法导⼊和导出包以重⽤导出的函数或类型:
import <packagename>
Golang 的标准包是 fmt,其中包含格式化和打印功能,如 Println().
Go 实现不重启热部署
根据系统的 SIGHUP 信号量,以此信号量触发进程重启,达到热更新的效果。
热部署我们需要考虑几个能力:
- 新进程启动成功,老进程不会有资源残留
- 新进程初始化的过程中,服务不会中断
- 新进程初始化失败,老进程仍然继续工作
- 同一时间,只能有一个更新动作执行
监听信号量的方法的环境是在 类 UNIX 系统中,在现在的 UNIX 内核中,允许多个进程同时监听一个端口。在收到 SIGHUP 信号量时,先 fork 出一个新的进程监听端口,同时等待旧进程处理完已经进来的连接,最后杀掉旧进程。
我基于这个思路,实现了一段示例代码,仓库地址:https://github.com/guowei-gong/tablefilp-example, 如果你希望动手来加深印象可以打开看看。
Go 中的指针强转
在 Golang 中无法使用指针类型对指针进行强制转换

但可以借助 unsafe 包中的 unsafe.Pointer 转换
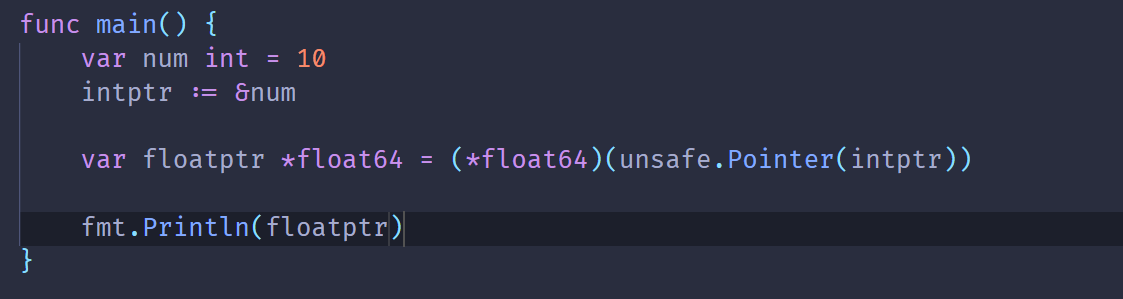
在 src/unsafe.go 中可以看到指针类型说明
// ArbitraryType 与 IntegerType 在此只用于文档描述,实际并不 unsafe 包中的一部分
// 表示任意 go 的表达式
type ArbitraryType int
// 表示任意 integer 类型
type IntegerType int
type Pointer *ArbitraryType
对于指针类型 Pointer 强调以下四种操作
- 指向任意类型的指针都可以被转化成 Pointer
- Pointer 可以转化成指向任意类型的指针
- uintptr 可以转化成 Pointer
- Pointer 可以转化成 uintptr
uintptr 在
src/builtin/builtin.go中定义
其后描述了六种指针转换的情形
其一:*Conversion of a T1 to Pointer to *T2
转换条件:
- T2 的数据类型不大于 T1
- T1、T2 的内存模型相同
因此对于 *int 不能强制转换 *float64 可以变化为 *int → unsafe.Pointer → *float64 的过程
Go 支持什么形式的类型转换?将整数转换为浮点数。
Go 支持显式类型转换以满足其严格的类型要求。
i := 55 //int
j := 67.8 //float64
sum := i + int(j)//j is converted to int
Golang 语言中== 的使用
package main
func main() {
var x interface{}
var y interface{} = []int{3, 5}
_ = x == x //输出true
_ = x == y //interface{}比较的是动态类型和动态值,输出false
_ = y == y //panic,切片不可比较
}
Go 语言实现小根堆
package main
import (
"container/heap"
"fmt"
)
type MinHeap []int
func (h MinHeap) Len() int { return len(h) }
func (h MinHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h MinHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *MinHeap) Push(x interface{}) {
*h = append(*h, x.(int))
}
func (h *MinHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[:n-1]
return x
}
func main() {
h := &MinHeap{2, 1, 5, 3, 4}
heap.Init(h)
fmt.Println("堆中最小的元素是:", (*h)[0])
heap.Push(h, 0)
fmt.Println("插入后最小的元素是:", (*h)[0])
min := heap.Pop(h).(int)
fmt.Println("弹出最小的元素是:", min)
}
Go 怎么实现 func 的自定义参数
在 golang中,type 可以定义任何自定义的类型
func 也是可以作为类型自定义的,type myFunc func(int) int,意思是自定义了一个叫 myFunc 的函数类型,这个函数的签名必须符合输入为 int,输出为 int。
golang通过type定义函数类型
通过 type 可以定义函数类型,格式如下
type typeName func(arguments) retType
函数类型也是一种类型,故可以将其定义为函数入参,在 go 语言中函数名可以看做是函数类型的常量,所以我们可以直接将函数名作为参数传入的函数中。
package main
import "fmt"
func add(a, b int) int {
return a + b
}
//sub作为函数名可以看成是 op 类型的常量
func sub(a, b int) int {
return a - b
}
//定义函数类型 op
type op func(a, b int) int
//形参指定传入参数为函数类型op
func Oper(fu op, a, b int) int {
return fu(a, b)
}
func main() {
//在go语言中函数名可以看做是函数类型的常量,所以我们可以直接将函数名作为参数传入的函数中。
aa := Oper(add, 1, 2)
fmt.Println(aa)
bb := Oper(sub, 1, 2)
fmt.Println(bb)
}
为什么 go 的变量申请类型是为了什么?
在 Go 编程语言中,数据类型用于声明函数和变量。
数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。
Go 的闭包语法
go语言的闭包可以理解为一个引用外部变量的匿名函数,Go语言中闭包是引用了自由变量的函数,被引用的自由变量和函数一同存在,即使已经离开了自由变量的环境也不会被释放或者删除,在闭包中可以继续使用这个自由变量,因此,简单的说:
函数 + 引用环境 = 闭包
同一个函数与不同引用环境组合,可以形成不同的实例,如下图:
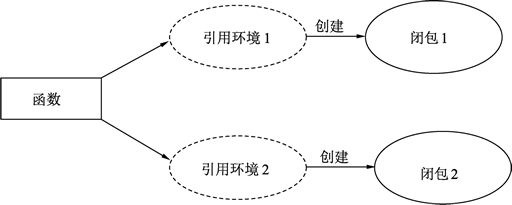
一个函数类型就像结构体一样,可以被实例化,函数本身不存储任何信息,只有与引用环境结合后形成的闭包才具有“记忆性”,函数是编译期静态的概念,而闭包是运行期动态的概念。
Go 语言中 int 占几个字节
Go语言中的int的大小是和操作系统位数相关的,如果是32位操作系统,int类型的大小就是4字节; 如果是64位操作系统,int类型的大小就是8个字节
Golang 程序启动过程
Golang 开发新手常犯的50个错误
https://blog.csdn.net/gezhonglei2007/article/details/52237582
go基础语法50问
https://juejin.cn/post/7160639446612705316
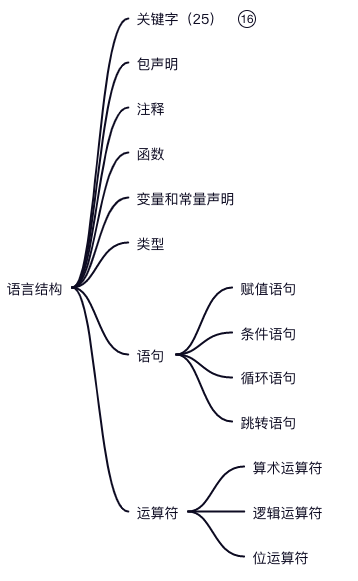
Go 程序的基本结构?
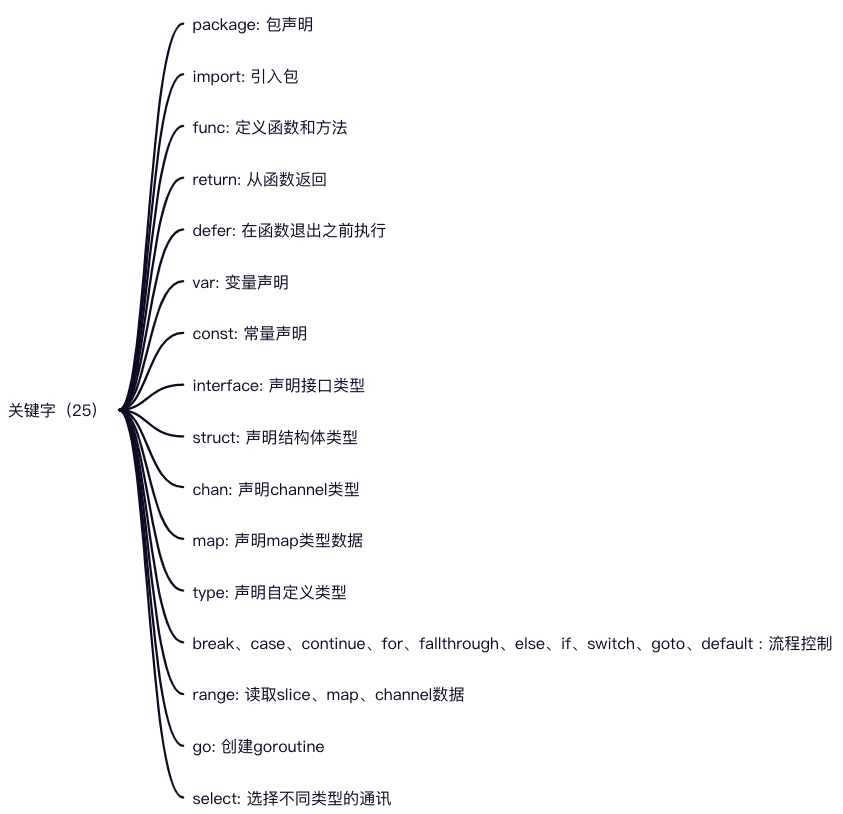
Go 有哪些关键字?
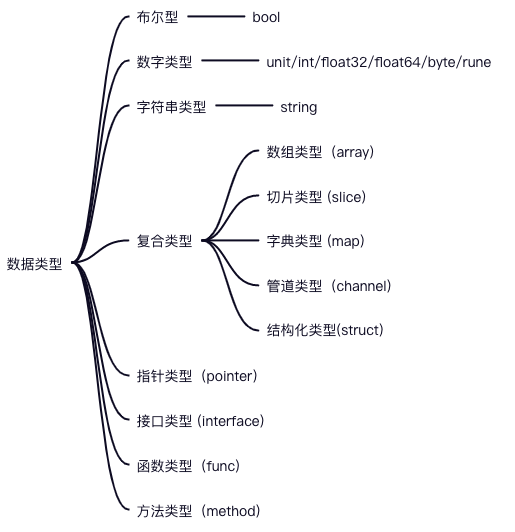
Go 有哪些数据类型?
Go 方法与函数的区别?
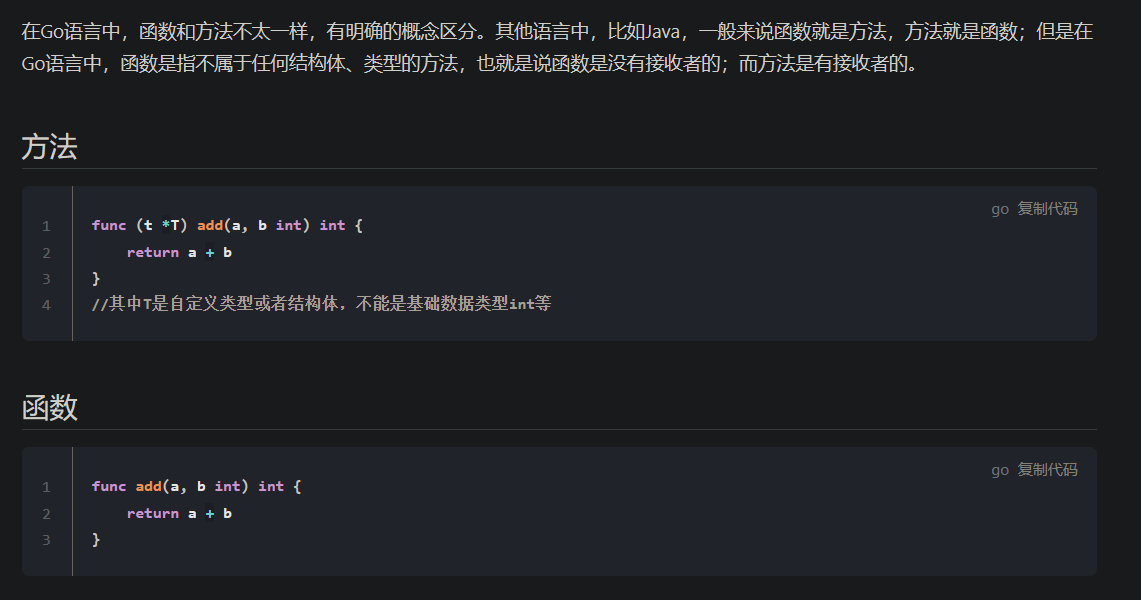
Go 方法值接收者和指针接收者的区别?
-
如果方法的接收者是指针类型,无论调用者是对象还是对象指针,修改的都是对象本身,会影响调用者;
-
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者;
package main
import "fmt"
type Person struct {
age int
}
// 如果实现了接收者是指针类型的方法,会隐含地也实现了接收者是值类型的IncrAge1方法。
// 会修改age的值
func (p *Person) IncrAge1() {
p.age += 1
}
// 如果实现了接收者是值类型的方法,会隐含地也实现了接收者是指针类型的IncrAge2方法。
// 不会修改age的值
func (p Person) IncrAge2() {
p.age += 1
}
// 如果实现了接收者是值类型的方法,会隐含地也实现了接收者是指针类型的GetAge方法。
func (p Person) GetAge() int {
return p.age
}
func main() {
// p1 是值类型
p := Person{age: 10}
// 值类型 调用接收者是指针类型的方法
p.IncrAge1()
fmt.Println(p.GetAge())
// 值类型 调用接收者是值类型的方法
p.IncrAge2()
fmt.Println(p.GetAge())
// ----------------------
// p2 是指针类型
p2 := &Person{age: 20}
// 指针类型 调用接收者是指针类型的方法
p2.IncrAge1()
fmt.Println(p2.GetAge())
// 指针类型 调用接收者是值类型的方法
p2.IncrAge2()
fmt.Println(p2.GetAge())
}
/*
11
11
21
21
*/
上述代码中:
实现了接收者是指针类型的 IncrAge 1 函数,不管调用者是值类型还是指针类型,都可以调用 IncrAge 1 方法,并且它的 age 值都改变了。
实现了接收者是指针类型的 IncrAge 2 函数,不管调用者是值类型还是指针类型,都可以调用 IncrAge 2 方法,并且它的 age 值都没有被改变。
通常我们使用指针类型作为方法的接收者的理由:
- 使用指针类型能够修改调用者的值。
- 使用指针类型可以避免在每次调用方法时复制该值,在值的类型为大型结构体时,这样做会更加高效。
Go 函数返回局部变量的指针是否安全?
一般来说,局部变量会在函数返回后被销毁,因此被返回的引用就成为了”无所指”的引用,程序会进入未知状态。
但这在 Go 中是安全的,Go 编译器将会对每个局部变量进行逃逸分析。如果发现局部变量的作用域超出该函数,则不会将内存分配在栈上,而是分配在堆上,因为他们不在栈区,即使释放函数,其内容也不会受影响。
package main
import "fmt"
func add(x, y int) *int {
res := 0
res = x + y
return &res
}
func main() {
fmt.Println(add(1, 2))
}
这个例子中,函数 add 局部变量 res 发生了逃逸。Res 作为返回值,在 main 函数中继续使用,因此 res 指向的内存不能够分配在栈上,随着函数结束而回收,只能分配在堆上。
编译时可以借助选项 -gcflags=-m,查看变量逃逸的情况
./main.go:6:2: res escapes to heap:
./main.go:6:2: flow: ~r2 = &res:
./main.go:6:2: from &res (address-of) at ./main.go:8:9
./main.go:6:2: from return &res (return) at ./main.go:8:2
./main.go:6:2: moved to heap: res
./main.go:12:13: ... argument does not escape
0xc0000ae008
res escapes to heap 即表示 res 逃逸到堆上了。
Go 函数参数传递到底是值传递还是引用传递?
先说下结论:
Go 语言中所有的传参都是值传递(传值),都是一个副本,一个拷贝。
参数如果是非引用类型(int、string、struct 等这些),这样就在函数中就无法修改原内容数据;如果是引用类型(指针、map、slice、chan 等这些),这样就可以修改原内容数据。
是否可以修改原内容数据,和传值、传引用没有必然的关系。在 C++中,传引用肯定是可以修改原内容数据的,在 Go 语言里,虽然只有传值,但是我们也可以修改原内容数据,因为参数是引用类型
引用类型和引用传递是 2 个概念,切记!!!
什么是值传递?
将实参的值传递给形参,形参是实参的一份拷贝,实参和形参的内存地址不同。函数内对形参值内容的修改,是否会影响实参的值内容,取决于参数是否是引用类型
什么是引用传递?
将实参的地址传递给形参,函数内对形参值内容的修改,将会影响实参的值内容。Go 语言是没有引用传递的,在 C++中,函数参数的传递方式有引用传递。
例子:
package main
import "fmt"
func main() {
m := make(map[string]int)
m["age"] = 8
fmt.Printf("原始map的内存地址是:%p\n", &m)
modifyMap(m)
fmt.Printf("改动后的值是: %v\n", m)
}
func modifyMap(m map[string]int) {
fmt.Printf("函数里接收到map的内存地址是:%p\n", &m)
m["age"] = 9
}
/*
原始map的内存地址是:0xc00000e028
函数里接收到map的内存地址是:0xc00000e038
改动后的值是: map[age:9]
通过make函数创建的map变量本质是一个hmap类型的指针*hmap,所以函数内对形参的修改,会修改原内容数据(channel也如此)
*/
Go defer 关键字的实现原理?
定义:
Defer 能够让我们推迟执行某些函数调用,推迟到当前函数返回前才实际执行。Defer 与 panic 和 recover 结合,形成了 Go 语言风格的异常与捕获机制。
使用场景:
Defer 语句经常被用于处理成对的操作,如文件句柄关闭、连接关闭、释放锁
优点:
方便开发者使用
缺点:
有性能损耗
实现原理:
Go 1.14 中编译器会将 defer 函数直接插入到函数的尾部,无需链表和栈上参数拷贝,性能大幅提升。把 defer 函数在当前函数内展开并直接调用,这种方式被称为 open coded defer
源代码:
func A(i int) {
defer A1(i, 2*i)
if(i > 1) {
defer A2("Hello", "eggo")
}
// code to do something
return
}
func A1(a,b int) {
//......
}
func A2(m,n string) {
//......
}
编译后(伪代码):
func A(i int) {
// code to do something
if(i > 1){
A2("Hello", "eggo")
}
A1(i, 2*i)
return
}
代码示例:
1、函数退出前,按照先进后出的顺序,执行 defer 函数
package main
import "fmt"
// defer:延迟函数执行,先进后出
func main() {
defer fmt.Println("defer1")
defer fmt.Println("defer2")
defer fmt.Println("defer3")
defer fmt.Println("defer4")
fmt.Println("11111")
}
// 11111
// defer4
// defer3
// defer2
// defer1
2、panic 后的 defer 函数不会被执行(遇到 panic,如果没有捕获错误,函数会立刻终止)
package main
import "fmt"
// panic后的defer函数不会被执行
func main() {
defer fmt.Println("panic before")
panic("发生panic")
defer func() {
fmt.Println("panic after")
}()
}
// panic before
// panic: 发生panic
3、panic 没有被 recover 时,抛出的 panic 到当前 goroutine 最上层函数时,最上层程序直接异常终止
package main
import "fmt"
func F() {
defer func() {
fmt.Println("b")
}()
panic("a")
}
// 子函数抛出的panic没有recover时,上层函数时,程序直接异常终止
func main() {
defer func() {
fmt.Println("c")
}()
F()
fmt.Println("继续执行")
}
// b
// c
// panic: a
4、panic 有被 recover 时,当前 goroutine 最上层函数正常执行
package main
import "fmt"
func F() {
defer func() {
if err := recover(); err != nil {
fmt.Println("捕获异常:", err)
}
fmt.Println("b")
}()
panic("a")
}
func main() {
defer func() {
fmt.Println("c")
}()
F()
fmt.Println("继续执行")
}
// 捕获异常: a
// b
// 继续执行
// c
package main
import "fmt"
func main() {
defer func() {
if v := recover();v == 11 {
fmt.Println("v:",v)
}
fmt.Printf("defer1...")
}()
defer func() {
fmt.Printf("defer2...")
}()
array := [2]int{1,2}
fmt.Println("array: ",array[1])
panic(11)
}
//array: 2
//defer2...
//v: 11
//defer1...
- 执行过程是: 保存返回值 (若有)–>执行 defer(若有)–>执行 ret 跳转
func foo() (ret int) {
defer func() {
ret++
}()
return 0
}
- 延迟函数的参数在 defer 语句出现时就已经确定下来了
func a() {
i := 0
defer fmt.Println(i)
i++
return
}
注意:
执行顺序应该为 panic、defer、recover
- 发生 panic 的函数并不会立刻返回,而是先层层函数执行 defer,再返回。如果有办法将 panic 捕获到 panic,就正常处理(若是外部函数捕获到,则外部函数只执行 defer),如果没有没有捕获,程序直接异常终止。
- Go 语言提供了 recover 内置函数。前面提到,一旦 panic 逻辑就会走到 defer(defer 必须在 panic 的前面!)。调用 recover 函数将会捕获到当前的 panic,被捕获到的 panic 就不会向上传递了
- 在 panic 发生时,在前面的 defer 中通过 recover 捕获这个 panic,转化为错误通过返回值告诉方法调用者。
Go 内置函数 make 和 new 的区别?
首先纠正下 make 和 new 是内置函数,不是关键字
变量初始化,一般包括 2 步,变量声明 + 变量内存分配,var 关键字就是用来声明变量的,new 和 make 函数主要是用来分配内存的
Var 声明值类型的变量时,系统会默认为他分配内存空间,并赋该类型的零值
比如布尔、数字、字符串、结构体
如果指针类型或者引用类型的变量,系统不会为它分配内存,默认就是 nil。此时如果你想 直接使用,那么系统会抛异常,必须进行内存分配后,才能使用。
New 和 make 两个内置函数,主要用来分配内存空间,有了内存,变量就能使用了,主要有以下 2 点区别:
使用场景区别:
Make 只能用来分配及初始化类型为 slice、map、chan 的数据。
New 可以分配任意类型的数据,并且置零。
返回值区别:
Make 函数原型如下,返回的是 slice、map、chan 类型本身
这 3 种类型是引用类型,就没有必要返回他们的指针
func make(t Type, size ...IntegerType) Type
New 函数原型如下,返回一个指向该类型内存地址的指针
type slice struct {
array unsafe.Pointer
len int
cap int
}
Make 函数底层实现
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// NOTE: Produce a 'len out of range' error instead of a
// 'cap out of range' error when someone does make([]T, bignumber).
// 'cap out of range' is true too, but since the cap is only being
// supplied implicitly, saying len is clearer.
// See golang.org/issue/4085.
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}
函数功能:
- 检查切片占用的内存空间是否溢出。
- 调用
mallocgc在堆上申请一片连续的内存。
检查内存空间这里是根据切片容量进行计算的,根据当前切片元素的大小与切片容量的乘积得出当前内存空间的大小,检查溢出的条件:
- 内存空间大小溢出了
- 申请的内存空间大于最大可分配的内存
- 传入的
len小于0,cap的大小只小于 `len