第 4 章 Kafka Broker
Broker设计
我们都知道kafka能堆积非常大的数据,一台服务器,肯定是放不下的。由此出现的集群的概念,集群不仅可以让消息负载均衡,还能提高消息存取的吞吐量。kafka集群中,会有多台broker,每台broker分别在不同的机器上。 为了提高吞吐量,每个topic也会都多个分区,同时为了保持可靠性,每个分区还会有多个副本。这些分区副本被均匀的散落在每个broker上,其中每个分区副本中有一个副本为leader,其他的为follower。
Zookeeper
Zookeeper作用
Zookeeper在Kafka中扮演了重要的角色,kafka使用zookeeper进行元数据管理,保存broker注册信息,包括主题(Topic)、分区(Partition)信息等,选择分区leader。

Broker选举Leader
这里需要先明确一个概念leader选举,因为kafka中涉及多处选举机制,容易搞混,Kafka由三个方面会涉及到选举:
- broker(控制器)选leader
- 分区多副本选leader
- 消费者选Leader
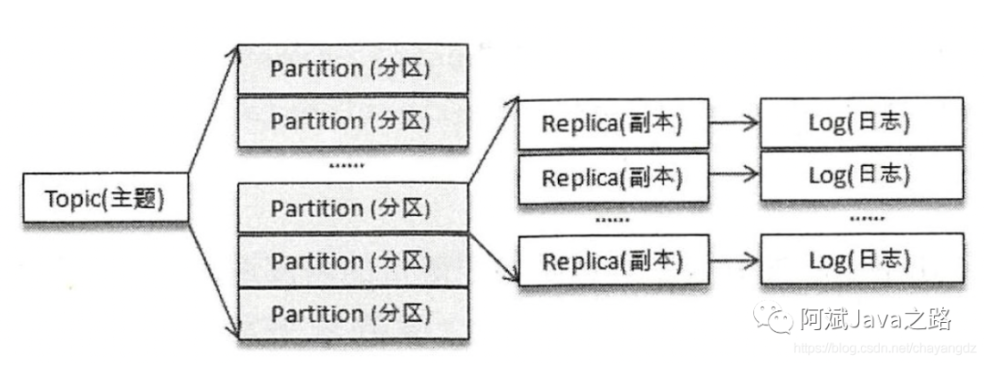
在kafka集群中由很多的broker(也叫做控制器),但是他们之间需要选举出一个leader,其他的都是follower。broker的leader有很重要的作用,诸如:创建、删除主题、增加分区并分配leader分区;集群broker管理,包括新增、关闭和故障处理;分区重分配(auto.leader.rebalance.enable=true,后面会介绍),分区leader选举。
每个broker都有唯一的brokerId,他们在启动后会去竞争注册zookeeper上的Controller结点,谁先抢到,谁就是broker leader。而其他broker会监听该结点事件,以便后续leader下线后触发重新选举。
简图:
- broker(控制器)选leader

详细图:
- broker(控制器)选leader
- 分区多副本选leader
模拟 Kafka 上下线,Zookeeper 中数据变化
(1)查看/kafka/brokers/ids 路径上的节点。
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids
[0, 1, 2](2)查看/kafka/controller 路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}(3)查看/kafka/brokers/topics/first/partitions/0/state 路径上的数据。
[zk: localhost:2181(CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18," isr":[0,1,2]}(4)停止 hadoop104 上的 kafka。
kafka-server-stop.sh(5)再次查看/kafka/brokers/ids 路径上的节点。
[zk: localhost:2181(CONNECTED) 3] ls /kafka/brokers/ids
[0, 1](6)再次查看/kafka/controller 路径上的数据。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}(7)再次查看/kafka/brokers/topics/first/partitions/0/state 路径上的数据。
[zk: localhost:2181(CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18," isr":[0,1]}(8)启动 hadoop104 上的 kafka。
kafka-server-start.sh -daemon ./config/server.properties(9)再次观察(1)、(2)、(3)步骤中的内容。
Broker重要参数

节点服役和退役
服役新节点
(1) 启动一台新的KafKa服务端(加入原有的Zookeeper集群)
(2) 查看原有的 分区信息 describe
$ kafka-topics.sh --bootstrap-server 47.106.86.64:9092 --topic first --describe
Topic: first TopicId: 4DtkHPe4R1KyXNF7QyVqBA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 1 Replicas: 2,1,0 Isr: 1,0
Topic: first Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1
Topic: first Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,0(3) 指定需要均衡的主题
$ vim topics-to-move.json{
"topics": [
{"topic": "first"}
],
"version": 1
}
(4) 生成负载均衡计划(只是生成计划)
bin/kafka-reassign-partitions.sh --bootstrap-server 47.106.86.64:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generateCurrent partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[0,2,1],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[1,0,2],"log_dirs":["any","
any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","
any","any"]}]}(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
vim increase-replication-factor.json{"version":1,"partitions":[{"topic":"first","partition":0,"replic
as":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","par
tition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"to
pic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","
any","any"]}]}(5) 执行副本计划
kafka-reassign-partitions.sh --bootstrap-server 47.106.86.64:9092 --reassignment-json-file increase-replication-factor.json --execute(6) 验证计划
kafka-reassign-partitions.sh --bootstrap-server 47.106.86.64:9092 --reassignment-json-file increase-replication-factor.json --verifyStatus of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.
Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic first退役旧节点
1)执行负载均衡操作
先按照退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡。
不同于服役计划的 --broker-list "0,1,2" 退役了 Broker3 ;
kafka-reassign-partitions.sh --bootstrap-server 47.106.86.64:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate副本机制
副本基本信息
- Replica :副本,同一分区的不同副本保存的是相同的消息,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失 ,提高副本可靠性,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
- Leader :每个分区的多个副本中的”主副本”,生产者以及消费者只与 Leader 交互。
- Follower :每个分区的多个副本中的”从副本”,负责实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,从 Follower 副本中重新选举新的 Leader 副本对外提供服务。
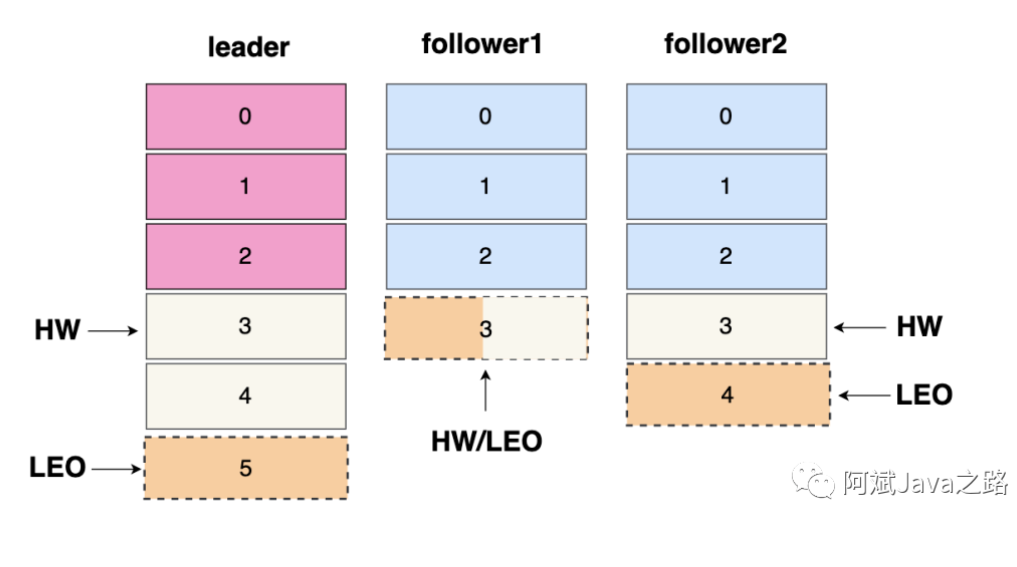
- AR:分区中的所有 Replica 统称为 AR = ISR +OSR
- ISR:所有与 Leader 副本保持一定程度同步的Replica(包括 Leader 副本在内)组成 ISR
- OSR:与 Leader 副本同步滞后过多的 Replica 组成了 OSR
- LEO:每个副本都有内部的LEO,代表当前队列消息的最后一条偏移量offset + 1。
- HW:高水位,代表所有ISR中的LEO最低的那个offset,也是消费者可见的最大消息offset。
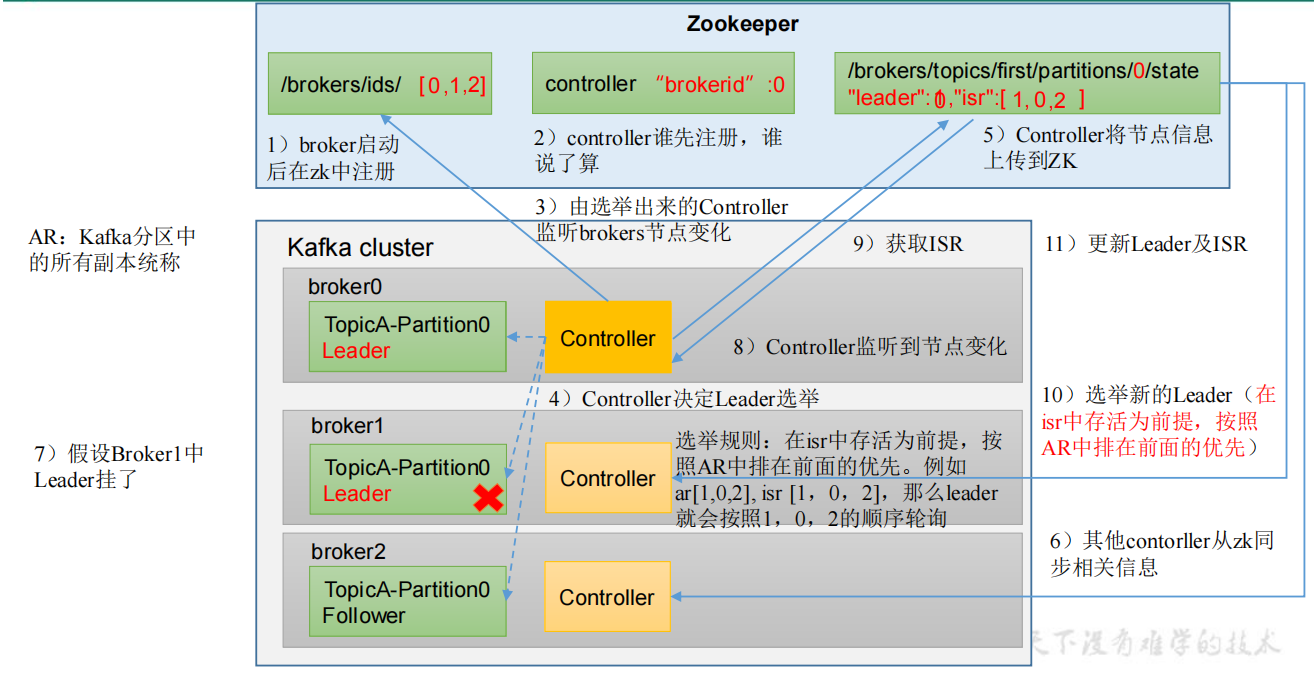
副本选举Leader
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader (4.2.2) ,负责管理集群Broker 的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。
Broker中Controller 的信息同步工作是依赖于 Zookeeper 的 ./broker/topic 目录下的信息。
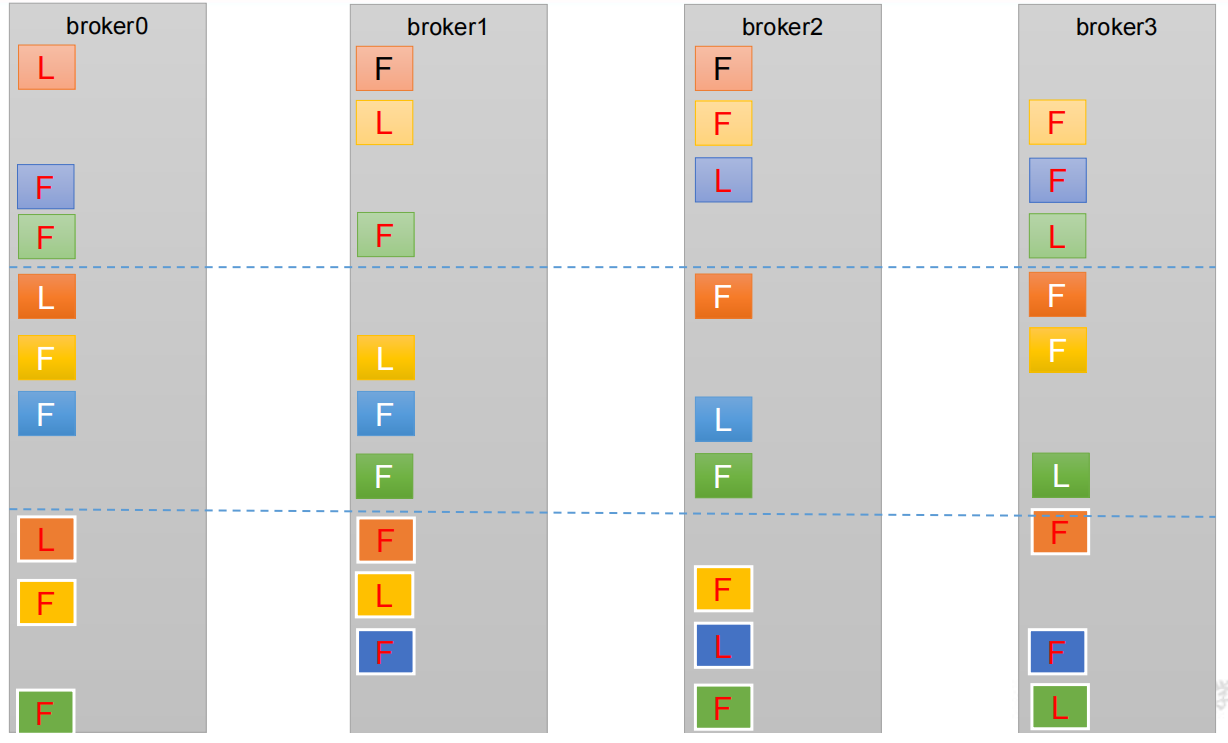
结论先行: 如果leader副本下线, 会在ISR队列中存活为前提,按照Replicas队列中前面优先的原则。
↓↓↓
(1)创建一个新的 topic,4 个分区,4 个副本
kafka-topics.sh --bootstrap-server 47.106.86.64:9092 --create --topic atguigu1 --partitions 4 --replication-factor 4(2)查看 Leader 分布情况
kafka-topics.sh --bootstrap-server 47.106.86.64:9092 --describe --topic atguigu1Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 3 Replicas: 3,0,2,1 Isr: 3,0,2,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,3,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,3,1,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0,3(3)停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况
kafka-server-stop.shkafka-topics.sh --bootstrap-server 47.106.86.64:9092 --describe --topic atguigu1Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,2,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,2,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1,2
Topic: atguigu1 Partition: 3 Leader: 2 Replicas: 2,1,0,3 Isr: 2,1,0(4)停止掉 hadoop104 的 kafka 进程,并查看 Leader 分区情况
kafka-server-stop.sh
kafka-topics.sh --bootstrap-server 47.106.86.64:9092 --describe --topic atguigu1Topic: atguigu1 TopicId: awpgX_7WR-OX3Vl6HE8sVg PartitionCount: 4 ReplicationFactor: 4
Configs: segment.bytes=1073741824
Topic: atguigu1 Partition: 0 Leader: 0 Replicas: 3,0,2,1 Isr: 0,1
Topic: atguigu1 Partition: 1 Leader: 1 Replicas: 1,2,3,0 Isr: 1,0
Topic: atguigu1 Partition: 2 Leader: 0 Replicas: 0,3,1,2 Isr: 0,1
Topic: atguigu1 Partition: 3 Leader: 1 Replicas: 2,1,0,3 Isr: 1,0副本故障处理
follower故障流程
如果follower落后leader过多,体现在落后时间 repca.lag.time.max.ms ,或者落后偏移量repca.lag.max.messages(由于kafka生成速度不好界定,后面取消了该参数),follower就会被移除ISR队列,等待该队列LEO追上HW,才会重新加入ISR中。

leader故障流程
旧Leader先被从ISR队列中踢出,然后从ISR中选出一个新的Leader来;此时为了保证多个副本之间的数据一致性,其他的follower会先将各自的log文件中高于HW的部分截取掉,然后从新的leader同步数据(由此可知这只能保证副本之间数据一致性,并不能保证数据不丢失或者不重复)。体现了设置ACK-all的重要性。

分区副本分配
如果 kafka 服务器只有 4 个节点,那么设置 kafka 的分区数大于服务器台数,在 kafka底层如何分配存储副本呢?
1)创建 16 分区,3 个副本
(1)创建一个新的 topic,名称为 second。
kafka-topics.sh --bootstrap-server 47.106.86.64:9092 --create --partitions 16 --replication-factor 3 --topic second(2)查看分区和副本情况。
kafka-topics.sh --bootstrap-server 47.106.86.64:9092 --describe --topic second
Topic: second4 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: second4 Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: second4 Partition: 2 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
Topic: second4 Partition: 3 Leader: 3 Replicas: 3,0,1 Isr: 3,0,1
Topic: second4 Partition: 4 Leader: 0 Replicas: 0,2,3 Isr: 0,2,3
Topic: second4 Partition: 5 Leader: 1 Replicas: 1,3,0 Isr: 1,3,0
Topic: second4 Partition: 6 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: second4 Partition: 7 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: second4 Partition: 8 Leader: 0 Replicas: 0,3,1 Isr: 0,3,1
Topic: second4 Partition: 9 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: second4 Partition: 10 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic: second4 Partition: 11 Leader: 3 Replicas: 3,2,0 Isr: 3,2,0
Topic: second4 Partition: 12 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: second4 Partition: 13 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: second4 Partition: 14 Leader: 2 Replicas: 2,3,0 Isr: 2,3,0
Topic: second4 Partition: 15 Leader: 3 Replicas: 3,0,1 Isr: 3,0,1
手动调整分区副本
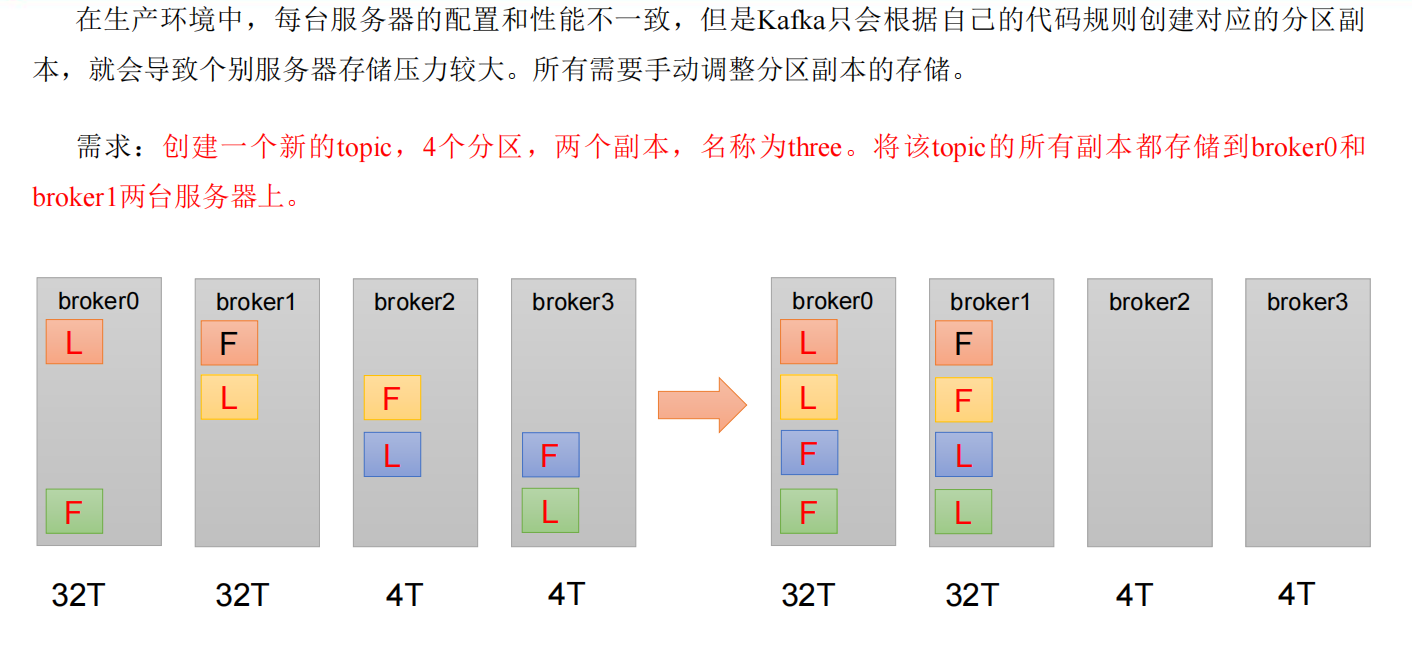
手动调整分区副本存储的步骤如下:
(1)创建一个新的 topic,名称为 three。
kafka-topics.sh --bootstrap-server 47.106.86.64:9092 --create --partitions 4 --replication-factor 2 --topic three(3)创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。
$ vim increase-replication-factor.json
输入如下内容:
{
"version":1,
"partitions":[
{"topic":"three","partition":0,"replicas":[0,1]},
{"topic":"three","partition":1,"replicas":[0,1]},
{"topic":"three","partition":2,"replicas":[1,0]},
{"topic":"three","partition":3,"replicas":[1,0]}]
}(4)执行副本存储计划。
kafka-reassign-partitions.sh --bootstrap-server 47.106.86.64:9092 --reassignment-json-file increase-replication-factor.json --execute(5)验证副本存储计划。
kafka-reassign-partitions.sh --bootstrap-server 47.106.86.64:9092 --reassignment-json-file increase-replication-factor.json --verify分区自动调整
一般情况下,我们的分区都是平衡散落在broker的,随着一些broker故障,会慢慢出现leader集中在某台broker上的情况,造成集群负载不均衡,这时候就需要分区平衡。
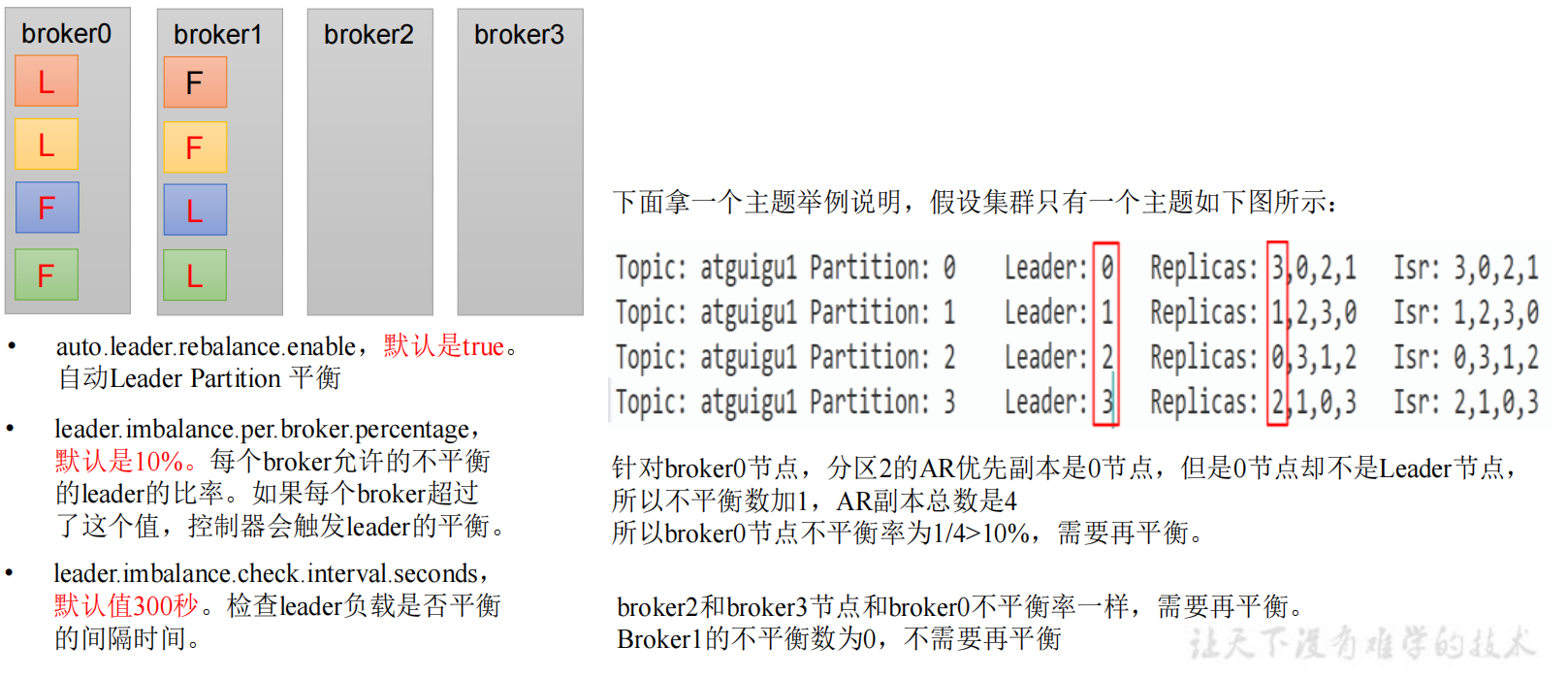
为了解决上述问题kafka出现了自动平衡的机制。kafka提供了下面几个参数进行控制:
auto.leader.rebalance.enable:自动leader parition平衡,默认是true;leader.imbalance.per.broker.percentage:每个broker允许的不平衡的leader的比率,默认是10%,如果超过这个值,控制器将会触发leader的平衡leader.imbalance.check.interval.seconds:检查leader负载是否平衡的时间间隔,默认是300秒- 但是在生产环境中是不开启这个自动平衡,因为触发leader partition的自动平衡会损耗性能,或者可以将触发自动平和的参数
leader.imbalance.per.broker.percentage的值调大点。
我们也可以通过修改配置,然后手动触发分区的再平衡。
增加副本因子
在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的增加需要先制定计划,然后根据计划执行。
不能通过命令行的方法添加副本。
1)创建 topic
bin/kafka-topics.sh --bootstrap-server 47.106.86.64:9092 --create --partitions 3 --replication-factor 1 --topic four2)手动增加副本存储
(1)创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)。
vim increase-replication-factor.json{"version":1,"partitions":[
{"topic":"four","partition":0,"replicas":[0,1,2]},
{"topic":"four","partition":1,"replicas":[0,1,2]},
{"topic":"four","partition":2,"replicas":[0,1,2]}]}(2)执行副本存储计划。
kafka-reassign-partitions.sh --bootstrap-server 47.106.86.64:9092 --reassignment-json-file increase-replication-factor.json --execute文件存储
存储结构
在Kafka中主题(Topic)是一个逻辑上的概念,分区(partition)是物理上的存在的。每个partition对应一个log文件,该log文件中存储的就是Producer生产的数据。Producer生产的数据会被不断追加到该log文件末端。为防止log文件过大导致数据定位效率低下,Kafka采用了分片和索引机制,将每个partition分为多个segment,每个segment默认1G( log.segment.bytes ), 每个segment包括.index文件、.log文件和**.timeindex**等文件。这些文件位于文件夹下,该文件命名规则为:topic名称+分区号。

Segment的三个文件需要通过特定工具打开才能看到信息
kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index
kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log 当log文件写入4k(这里可以通过log.index.interval.bytes设置)数据,就会写入一条索引信息到index文件中,这样的index索引文件就是一个稀疏索引,它并不会每条日志都建立索引信息。
当Kafka查询一条offset对应实际消息时,可以通过index进行二分查找,获取最近的低位offset,然后从低位offset对应的position开始,从实际的log文件中开始往后查找对应的消息。

时间戳索引文件,它的作用是可以查询某一个时间段内的消息,它的数据结构是:时间戳(8byte)+ 相对offset(4byte),如果要使用这个索引文件,先要通过时间范围找到对应的offset,然后再去找对应的index文件找到position信息,最后在遍历log文件,这个过程也是需要用到index索引文件的。

文件清理策略
Kafka将消息存储在磁盘中,为了控制磁盘占用空间的不断增加就需要对消息做一定的清理操作。Kafka 中每一个分区副本都对应一个Log,而Log又可以分为多个日志分段,这样也便于日志的清理操作。Kafka提供了两种日志清理策略。
- 日志删除(delete) :按照一定的保留策略直接删除不符合条件的日志分段。
- 日志压缩(compact) :针对每个消息的key进行整合,对于有相同key的不同value值,只保留最后一个版本。
我们可以通过修改broker端参数 log.cleanup.policy 来进行配置
日志删除
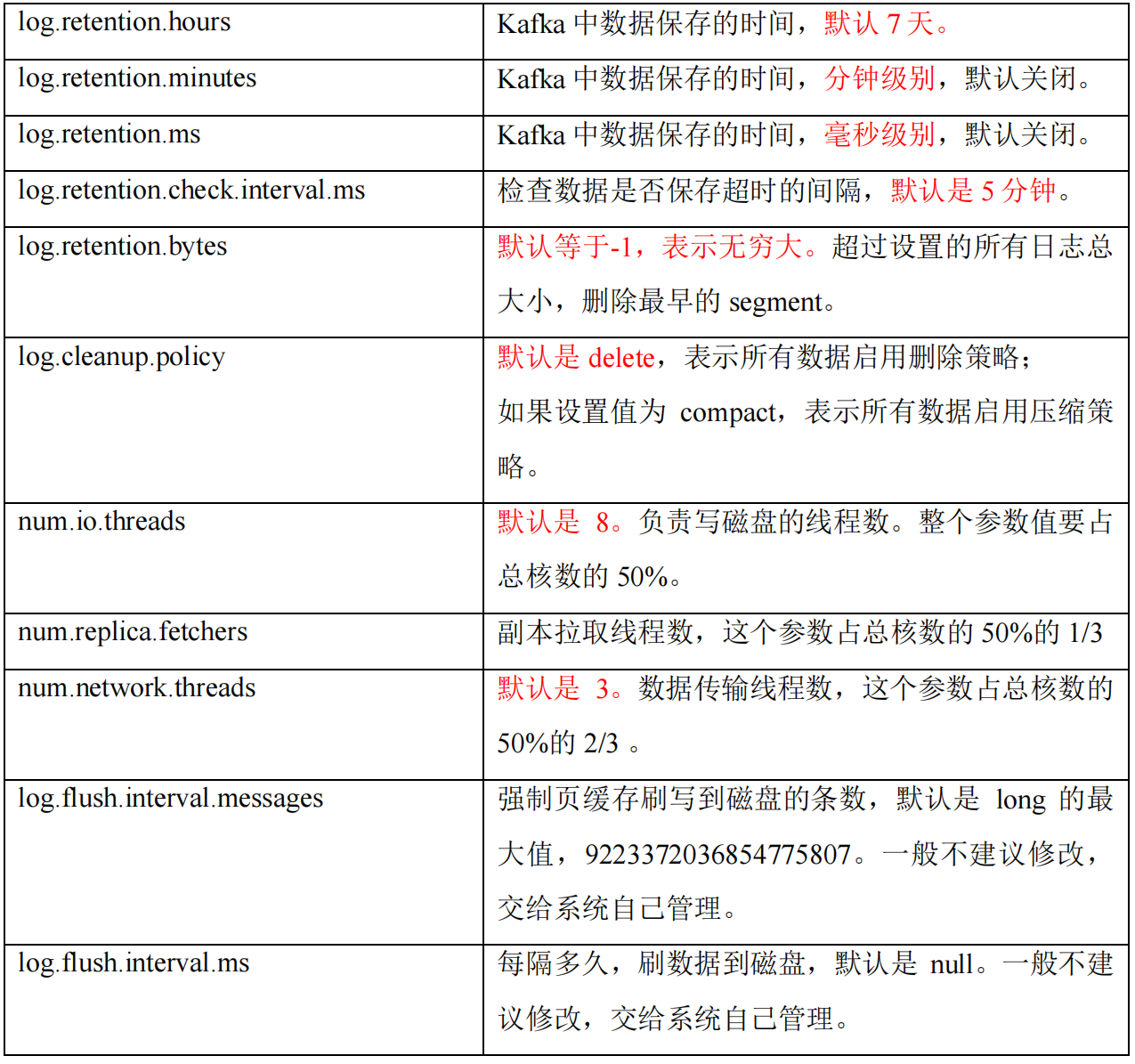
kafka中默认的日志保存时间为7天,可以通过调整如下参数修改保存时间。
log.retention.hours:最低优先级小时,默认7天log.retention.minutes:分钟log.retention.ms:最高优先级毫秒log.retention.check.interval.ms:负责设置检查周期,默认5分钟file.delete.delay.ms:延迟执行删除时间log.retention.bytes:当设置为-1时表示运行保留日志最大值(相当于关闭);当设置为1G时,表示日志文件最大值
具体的保留日志策略有三种:
基于时间策略
日志删除任务会周期检查当前日志文件中是否有保留时间超过设定的阈值来寻找可删除的日志段文件集合;这里需要注意log.retention参数的优先级:log.retention.ms > log.retention.minutes > log.retention.hours,默认只会配置log.retention.hours参数,值为168即为7天。
删除过期的日志段文件,并不是简单的根据日志段文件的修改时间计算,而是要根据该日志段中最大的时间戳来计算的,首先要查询该日志分段所对应的时间戳索引文件,查找该时间戳索引文件的最后一条索引数据,如果时间戳大于0就取值,否则才会使用最近修改时间。
在删除的时候先从Log对象所维护的日志段的跳跃表中移除要删除的日志段,用来确保已经没有线程来读取这些日志段;接着将日志段所对应的所有文件,包括索引文件都添加上**.deleted的后缀;最后交给一个以delete-file命名的延迟任务来删除这些以.deleted为后缀的文件,默认是1分钟执行一次,可以通过file.delete.delay.ms**来配置。
基于日志大小策略
日志删除任务会周期性检查当前日志大小是否超过设定的阈值(log.retention.bytes,默认是-1,表示无穷大),就从第一个日志分段中寻找可删除的日志段文件集合。如果超过阈值,
基于日志起始偏移量
该策略判断依据是日志段的下一个日志段的起始偏移量 baseOffset是否小于等于 logStartOffset,如果是,则可以删除此日志分段。这里说一下logStartOffset,一般情况下,日志文件的起始偏移量 logStartOffset等于第一个日志分段的 baseOffset,但这并不是绝对的,logStartOffset的值可以通过 DeleteRecordsRequest请求、使用 kafka-delete-records.sh 脚本、日志的清理和截断等操作进行修改。
日志压缩
日志压缩对于有相同key的不同value值,只保留最后一个版本。如果应用只关心 key对应的最新 value值,则可以开启 Kafka相应的日志清理功能,Kafka会定期将相同 key的消息进行合并,只保留最新的 value值。
- log.cleanup.policy = compact 所有数据启用压缩策略
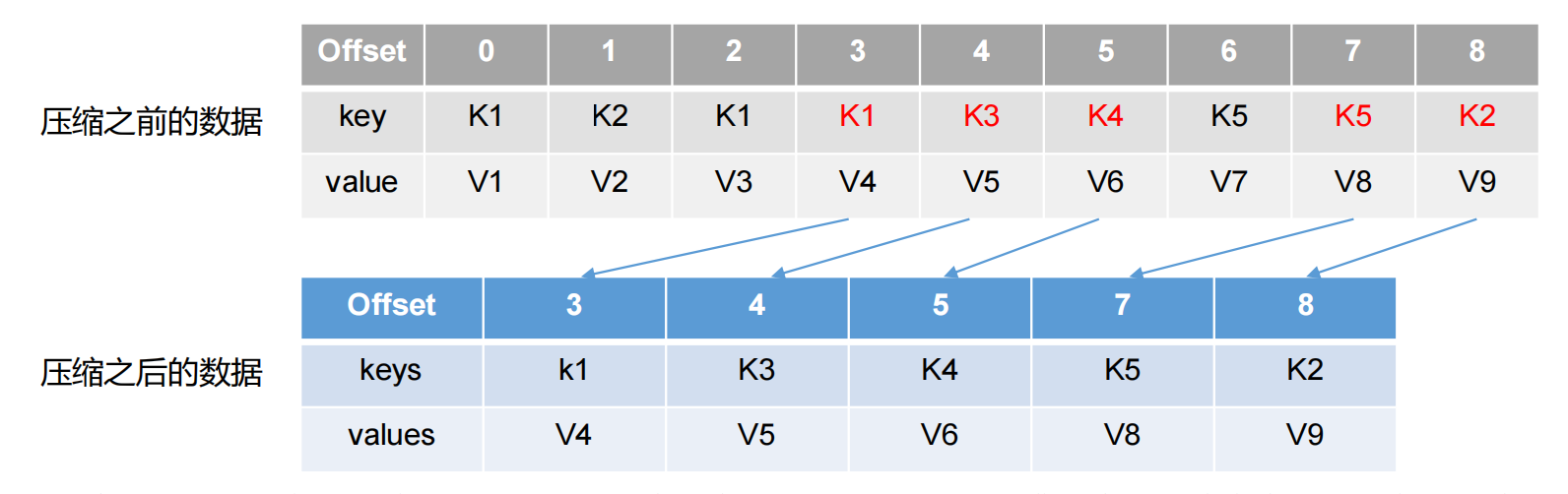
这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
Kafka高效读数据
kafka之所以可以快速读写的原因如下:
- kafka是分布式集群,采用分区方式,并行操作
- 读取数据采用稀疏索引,可以快速定位消费数据
- 顺序写磁盘
- 页缓冲和零拷贝
顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。

页缓存与零拷贝
kafka高效读写的原因很大一部分取决于页缓存和零拷贝
页缓存
在 Kafka 中,大量使用了 PageCache, 这也是 Kafka 能实现高吞吐的重要因素之一。
首先看一下读操作,当一个进程要去读取磁盘上的文件内容时,操作系统会先查看要读取的数据页是否缓冲在PageCache 中,如果存在则直接返回要读取的数据,这就减少了对于磁盘 I/O的 操作;但是如果没有查到,操作系统会向磁盘发起读取请求并将读取的数据页存入 PageCache 中,之后再将数据返回给进程,就和使用redis缓冲是一个道理。
接着写操作和读操作是一样的,如果一个进程需要将数据写入磁盘,操作系统会检查数据页是否在PageCache 中已经存在,如果不存在就在 PageCache中添加相应的数据页,接着将数据写入对应的数据页。另外被修改过后的数据页也就变成了脏页,操作系统会在适当时间将脏页中的数据写入磁盘,以保持数据的一致性。
具体的刷盘机制可以通过 log.flush.interval messages,log.flush .interval .ms 等参数来控制。同步刷盘可以提高消息的可靠性,防止由于机器 掉电等异常造成处于页缓存而没有及时写入磁盘的消息丢失。一般并不建议这么做,刷盘任务就应交由操作系统去调配,消息的可靠性应该由多副本机制来保障,而不是由同步刷盘这 种严重影响性能的行为来保障 。
零拷贝
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数,通常使用在IO读写过程中。常规应用程序IO过程如下图,会经过四次拷贝:
- 数据从磁盘经过DMA(直接存储器访问)到内核的Read Buffer;
- 内核态的Read Buffer到用户态应用层的Buffer
- 用户态的Buffer到内核态的Socket Buffer
- Socket Buffer到网卡的NIC Buffer
从上面的流程可以知道内核态和用户态之间的拷贝相当于执行两次无用的操作,之间切换也会花费很多资源;当数据从磁盘经过DMA 拷贝到内核缓存(页缓存)后,为了减少CPU拷贝的性能损耗,操作系统会将该内核缓存与用户层进行共享,减少一次CPU copy过程,同时用户层的读写也会直接访问该共享存储,本身由用户层到Socket缓存的数据拷贝过程也变成了从内核到内核的CPU拷贝过程,更加的快速,这就是零拷贝,IO流程如下图。
甚至如果我们的消息存在页缓存PageCache中,还避免了硬盘到内核的拷贝过程,更加一步提升了消息的吞吐量。 (大概就理解成传输的数据只保存在内核空间,不需要再拷贝到用户态的应用层)

Java的JDK NIO中方法transferTo()方法就能够实现零拷贝操作,这个实现依赖于操作系统底层的sendFile()实现的